PTE-A.com
세상을 바꾸는 작은 힘
Spoken Language Assessment Technology V1.7
안녕하세요.
PTE 시험이 Computer base 시험이기 때문에, Pearson 이 어떠한 spoken language assessment technology 를 사용하는지를 알고,
그 방법에 맞게 준비를 할 수만 있다면, 스피킹에서 만큼은 많은 분들이 쉽게 원하는 점수를 얻지 않을까 생각을 하고 있는데요.
인터넷에 떠돌아 다니는 자료들을 읽어보고 이해하려고 노력 중이지만, 저의 전문분야가 아니라서 쉽지만은 않군요.
먼저, 간단한 그림으로 수험생의 speech 가 어떻게 컨텐츠와 발음,유창성 의 점수를 채점하는 지에 대해 아래의 그림에서 설명이 되어 있습니다.
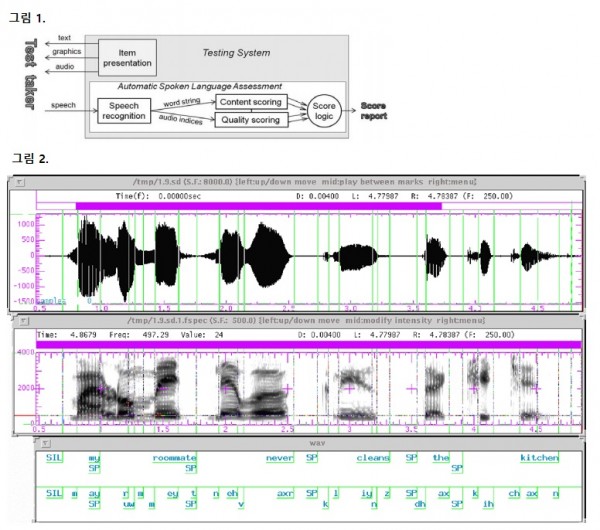
[그림 1] Speech recognition system 에 의해 word string 과 audio indices 로 분류가 되고, word string 은 content 로 채점이 되며, audio indices 는 Quality scoring 으로 채점되는 것으로 보입니다.
이 부분에서 저희가 speechnotes 와 같은 프로그램으로 speaking 이 어느 정도 인식이 되는지를 연습하는 것은 contents scoring 과 밀접한 관련된 것으로 이해가 됩니다.몇몇 분들이 speechnotes 와 같은 어플에서 80~90% 인식이 되는데, 발음과 유창성 점수가 10인 이유는 측정기준이 다르기 때문이라고 생각이 됩니다. 발음과 유창성 점수가 10/10 이어도 스피킹 점수는 10점 이상씩 나온 이유는 Contents 점수는 어느 정도 획득하기 때문이라고 생각이 됩니다.
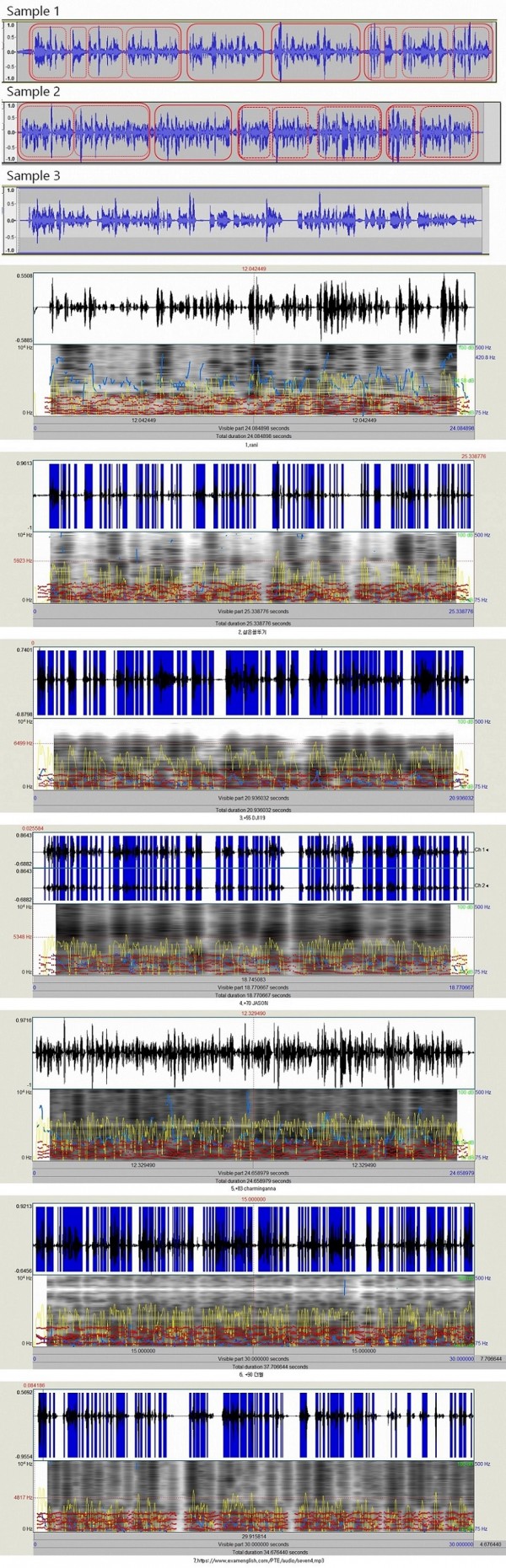
[그림 2] Pearson 의 공식 Score Guide 에도 언급되어 있는 Versant system은 특허권을 가진 HTK ( Hidden Markov Model Toolkit ) 기반으로 되어있습니다.
*The first mapping consists of a waveform representation of the spoken sentence;
this consists of a time-series plot of the energy of sounds produced by the test taker.
*The second mapping is a spectrogram that represents the pitch pattern in the response, where darker shading represents more stress placed on the phoneme.
*The third plot represents the phone sounds which were actually “understood” by the speech recogniser (“My roommate never cleans the kitchen”).
*From this, the Versant speech processors can disambiguate a number of features of the spoken responses, such as duration, hesitations, syllables, clarity of phone production and some subphonemic sounds are recorded and measured.
발음과 유창성 점수채점을 위해 a large set of base physical measures (e.g. durations of segments, syllables, and silences, and spectral properties of segments and subsegments) 들이 사용되는데, 이것들은 다양한 연령대, 엑센트, 성별 로 구분되어진 native acoustic models 들로 구성되어 있습니다.
이처럼 발음과 유창성 점수와 관련된 Quality scoring 은 audio indices 와 같은 Acoustic model을 사용하는데, 이 부분은
1.flyingJ 님이 소개해주신 audacity
2.Praat
과 같은 프로그램으로 비교 분석하는 방법이 많은 도움이 될 수 있습니다.
*Refer to http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=2628#c_2633
audacity 을 이용한 발음교정방법들은 유튜브에서 쉽게 찾을 수 있으며, native acoustic models 들이 될 수 있는 RA sample 파일들을 audacity 에서 open 하여, shadowing 방법과 같은 방식으로 녹음을 병행하면 도움이 될 것 같습니다.
*Refer to https://www.youtube.com/watch?v=jEStFcRQSbE&t=30s
and https://luckytoilet.wordpress.com/tag/english/
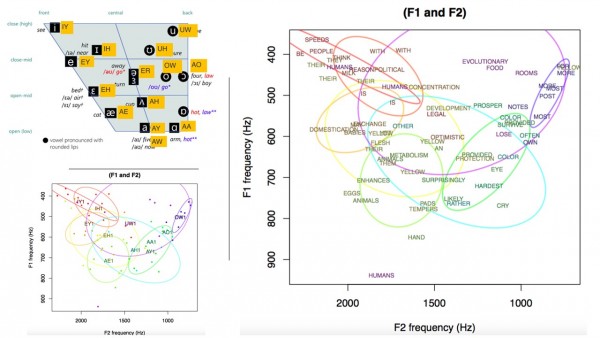
*실선:문장의 마침표로 구분, 점선:쉼표로 구분
이곳 사이트에서 올려져 있는 Sample RA 음성파일들 중 몇개의 파형을 분석해 보면,
Sample 1. 삶은 꼴뚜기님의 Sample 은 RA 유창성43 을 받으신 적이 있으셔서 그런지, phrasing은 나쁘지 않아보였습니다. 음성파일의 잡음(웅~)을 제거하였음에도 불구하고, 문장의 끝을 낮추면서 길게 끄는 습관때문인지, 파동이 정확히 끝나지 않고 다음문장과 연장이 됩니다.
Sample 2 [+79 ] 고수님의 Sample 이며, phrasing 이 눈에 띄게 잘되어 있습니다. 특이하게 마침표와 쉼표사이에 호흡의 파동이 잡히지만, 이것이 어떠한 영향을 주는지는 모르겠습니다.
Sample 3. Jason의 3.wav 파일입니다. 어느 부분이 쉼표이고, 마침표인지 눈으로 확인해 보세요.
Sample 3 밑의 이미지는 Praat tool 에서 만들어 졌으며, 이미지별로 상단은 wave form, 하단은 스페트럼 부분으로 나누어져 있습니다. 스펙트럼 부분에서는 intensity,pitch,formant 를 동시에 캡쳐할 수 있습니다. 스펙트럼 부분은 특히 다음과 같이 구분됩니다.
-노란색선: Intensity / 음의 세기 (dB)
-파란색선: Pitch / 음의 높이 (Hz)
여성의 목소리는 성대의 진동이 빠르기 때문에 피치의 움직임이 크게 나타나고, 남성의 피치의 움직임이 크지 않습니다. 피치의 움직임의 크기보다는 피치의 모양이 원어민의 모양과 비슷하게 만드는 것이 중요합니다.
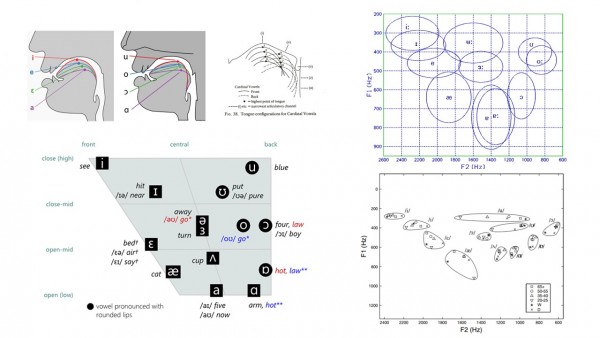
-빨강색점: Formant / F1, F2, F3, F4 에 의해 입안의 모양을 측정하여 vowel 사운드를 식별 (Hz) ( Number of Formants = Male:5~6 , Female:3~4 )
*F1 : 입벌림의 모양에 의해 변화
*F2 : 입술의 움직임에 의해 변화 *강좌:http://fonetiks.info/praat/form.mp4
https://home.cc.umanitoba.ca/~krussll/phonetics/acoustic/formants.html
The frequency of the first formant is mostly determined by the height of the tongue body:
high F1 = low vowel (i.e., high frequency F1 = low tongue body)
low F1 = high vowel (i.e., low frequency F1 = high tongue body)
The frequency of the second formant is mostly determined by the frontness/backness of the tongue body:
high F2 = front vowel
low F2 = back vowel
바닥선으로 부터 첫번째 빨강색 수평 점선이 F1, 그 위의 선이 F2,F3,F4 입니다.
Praat 과 함께 다양한 방법들을 통하여 음성분석을 수행했던 내용들을 아래에 첨부합니ㅏㄷ.
*삶은 꼴뚜기님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=3348&page=6
*BK0423 님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=3654&page=2
구루미1님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=board&wr_id=5662&page=3
*솜바님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=3850&page=3
*rickylikescoffee님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=board&wr_id=6001
* Sample 음성파일을 올리신 분들의 사전 동의없이 음성파일 분석을 위해서 사용했는데,삭제를 원하시는 분들은 알려주시기 바랍니다. 다시 한번 감사드립니다.
이글은 제가 좀더 공부를 한 이후에 다시 v2 로 업데이트하도록 하겠습니다.
PTE 시험이 Computer base 시험이기 때문에, Pearson 이 어떠한 spoken language assessment technology 를 사용하는지를 알고,
그 방법에 맞게 준비를 할 수만 있다면, 스피킹에서 만큼은 많은 분들이 쉽게 원하는 점수를 얻지 않을까 생각을 하고 있는데요.
인터넷에 떠돌아 다니는 자료들을 읽어보고 이해하려고 노력 중이지만, 저의 전문분야가 아니라서 쉽지만은 않군요.
먼저, 간단한 그림으로 수험생의 speech 가 어떻게 컨텐츠와 발음,유창성 의 점수를 채점하는 지에 대해 아래의 그림에서 설명이 되어 있습니다.

[그림 1] Speech recognition system 에 의해 word string 과 audio indices 로 분류가 되고, word string 은 content 로 채점이 되며, audio indices 는 Quality scoring 으로 채점되는 것으로 보입니다.
이 부분에서 저희가 speechnotes 와 같은 프로그램으로 speaking 이 어느 정도 인식이 되는지를 연습하는 것은 contents scoring 과 밀접한 관련된 것으로 이해가 됩니다.몇몇 분들이 speechnotes 와 같은 어플에서 80~90% 인식이 되는데, 발음과 유창성 점수가 10인 이유는 측정기준이 다르기 때문이라고 생각이 됩니다. 발음과 유창성 점수가 10/10 이어도 스피킹 점수는 10점 이상씩 나온 이유는 Contents 점수는 어느 정도 획득하기 때문이라고 생각이 됩니다.
[그림 2] Pearson 의 공식 Score Guide 에도 언급되어 있는 Versant system은 특허권을 가진 HTK ( Hidden Markov Model Toolkit ) 기반으로 되어있습니다.
*The first mapping consists of a waveform representation of the spoken sentence;
this consists of a time-series plot of the energy of sounds produced by the test taker.
*The second mapping is a spectrogram that represents the pitch pattern in the response, where darker shading represents more stress placed on the phoneme.
*The third plot represents the phone sounds which were actually “understood” by the speech recogniser (“My roommate never cleans the kitchen”).
*From this, the Versant speech processors can disambiguate a number of features of the spoken responses, such as duration, hesitations, syllables, clarity of phone production and some subphonemic sounds are recorded and measured.
발음과 유창성 점수채점을 위해 a large set of base physical measures (e.g. durations of segments, syllables, and silences, and spectral properties of segments and subsegments) 들이 사용되는데, 이것들은 다양한 연령대, 엑센트, 성별 로 구분되어진 native acoustic models 들로 구성되어 있습니다.
이처럼 발음과 유창성 점수와 관련된 Quality scoring 은 audio indices 와 같은 Acoustic model을 사용하는데, 이 부분은
1.flyingJ 님이 소개해주신 audacity
2.Praat
과 같은 프로그램으로 비교 분석하는 방법이 많은 도움이 될 수 있습니다.
*Refer to http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=2628#c_2633
audacity 을 이용한 발음교정방법들은 유튜브에서 쉽게 찾을 수 있으며, native acoustic models 들이 될 수 있는 RA sample 파일들을 audacity 에서 open 하여, shadowing 방법과 같은 방식으로 녹음을 병행하면 도움이 될 것 같습니다.
*Refer to https://www.youtube.com/watch?v=jEStFcRQSbE&t=30s
and https://luckytoilet.wordpress.com/tag/english/

*실선:문장의 마침표로 구분, 점선:쉼표로 구분
이곳 사이트에서 올려져 있는 Sample RA 음성파일들 중 몇개의 파형을 분석해 보면,
Sample 1. 삶은 꼴뚜기님의 Sample 은 RA 유창성43 을 받으신 적이 있으셔서 그런지, phrasing은 나쁘지 않아보였습니다. 음성파일의 잡음(웅~)을 제거하였음에도 불구하고, 문장의 끝을 낮추면서 길게 끄는 습관때문인지, 파동이 정확히 끝나지 않고 다음문장과 연장이 됩니다.
Sample 2 [+79 ] 고수님의 Sample 이며, phrasing 이 눈에 띄게 잘되어 있습니다. 특이하게 마침표와 쉼표사이에 호흡의 파동이 잡히지만, 이것이 어떠한 영향을 주는지는 모르겠습니다.
Sample 3. Jason의 3.wav 파일입니다. 어느 부분이 쉼표이고, 마침표인지 눈으로 확인해 보세요.
Sample 3 밑의 이미지는 Praat tool 에서 만들어 졌으며, 이미지별로 상단은 wave form, 하단은 스페트럼 부분으로 나누어져 있습니다. 스펙트럼 부분에서는 intensity,pitch,formant 를 동시에 캡쳐할 수 있습니다. 스펙트럼 부분은 특히 다음과 같이 구분됩니다.
-노란색선: Intensity / 음의 세기 (dB)
-파란색선: Pitch / 음의 높이 (Hz)
여성의 목소리는 성대의 진동이 빠르기 때문에 피치의 움직임이 크게 나타나고, 남성의 피치의 움직임이 크지 않습니다. 피치의 움직임의 크기보다는 피치의 모양이 원어민의 모양과 비슷하게 만드는 것이 중요합니다.
-빨강색점: Formant / F1, F2, F3, F4 에 의해 입안의 모양을 측정하여 vowel 사운드를 식별 (Hz) ( Number of Formants = Male:5~6 , Female:3~4 )
*F1 : 입벌림의 모양에 의해 변화
*F2 : 입술의 움직임에 의해 변화 *강좌:http://fonetiks.info/praat/form.mp4
https://home.cc.umanitoba.ca/~krussll/phonetics/acoustic/formants.html
The frequency of the first formant is mostly determined by the height of the tongue body:
high F1 = low vowel (i.e., high frequency F1 = low tongue body)
low F1 = high vowel (i.e., low frequency F1 = high tongue body)
The frequency of the second formant is mostly determined by the frontness/backness of the tongue body:
high F2 = front vowel
low F2 = back vowel
바닥선으로 부터 첫번째 빨강색 수평 점선이 F1, 그 위의 선이 F2,F3,F4 입니다.
Praat 과 함께 다양한 방법들을 통하여 음성분석을 수행했던 내용들을 아래에 첨부합니ㅏㄷ.


*삶은 꼴뚜기님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=3348&page=6
*BK0423 님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=3654&page=2
구루미1님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=board&wr_id=5662&page=3
*솜바님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=qna&wr_id=3850&page=3
*rickylikescoffee님의 음성파일 분석
http://pte-a.com/bbs/board.php?bo_table=board&wr_id=6001
* Sample 음성파일을 올리신 분들의 사전 동의없이 음성파일 분석을 위해서 사용했는데,삭제를 원하시는 분들은 알려주시기 바랍니다. 다시 한번 감사드립니다.
이글은 제가 좀더 공부를 한 이후에 다시 v2 로 업데이트하도록 하겠습니다.
얼마전 성공후기에 남기신 님도 말씀하셨지만, RA 할때 긴건 5초 남고, 짧은건 10초 정도 남을 정도로 하셨는데도 플루언시가 좋게 나온님 경우를 보고 생각이 난건데, 웨이브 파장이 빠른사람은 짧게 끝나고 상대적으로 조금 천천히 말한사람은 시간(sec)때문에 웨이브파장이 길게 되잖아요. 그럼 기계가 점수채점을 위해 분석할때, 40초 안에만 끝나면 마이너스는 없다고 가정하에, 만점의 웨이브파장을 기준(예로, 20~26초)으로, 길게 말한 스피치 웨이브파장(35초)을 만점기준 웨이브파장과 길이를 비슷하게 맞춰서? 줄여서? ..그 파장의 높낮이가 흡사하면 점수가 높게 나오는걸까요?
제가 audacity 써본적이 없어서 설명을 쉽게 못드리겠네요.
< - < - < - < - < ---> <-<-<-<-<
위같이 파장을 늘리거나 줄일수 있을것같아서요. 같은 시간배열로 세팅하고 줄이고 늘리면 파장이 올라간곳 내려간곳 일치하는지 안하는지 비교를 할수 있지않을까요?
발음한 자음과 모음 (특정언어에 국한되지 않은 국제적인 발음기호로) 을 찾아낼수있어요. 이걸로 발음한 단어 찾는거구요 이 목소리의 평균 pitch 를 잡아서 intonation이나 word stress 가 틀렸는지 맞았는지도 알수있어요. phonetics 공부한지 2년됐더니 다까먹었네요.. 기회가되면 저도 한번 자세히 올려보도록 하겠습니다.
다만 우려가 되는것은 일반인이 이러한 프로그램을 썼을때
어떤방식으로 모범샘플과 같은 파장,hz 를 만드는지 몰라서
목소리 크기만 또는 음만 왔다갔다하게될 가능성이 있다는거죠..ㅠㅠ
같은 모음도 항상 똑같이 발음되는건 아니라는 점도 고려해서 학생분들께 조언드리면 좋을것 같습니다. 예를 들어서 같은 a 라고 해서 apple과 fall이 같게 발음되는 건 아니죠. 근데 학생분들이 보시기에는 내가 a를 잘못발음하고 있구나 라고 단편적으로 해석할 위험이 있습니다. 학생이 적극적으로 활용하기 위해서는 1, 한 단어 한 단어씩 그 자체의 들리는 발음을 그대로 공부하시거나 혹은 2, (알파벳그대로가 아닌) 발음기호로 보면서 공부해야한다는 점을 추가로 언급하시면 더 좋을것 같습니다. ^^